Week 1 - The Basics
What is computational biology?
Computational biology is an interdisciplinary field that leverages the power of computer science, mathematics, and statistics to understand and model biological systems. It does not replace traditional biological lab research; rather, it complements it by helping translate large data into a testable hypothesis in labs.
Why computational biology?
As you may know, the goal of biological sciences is to understand how living organisms (plants, animals, bacteria, etc.) work. However, even the simplest of organisms are complex. A simplistic view of the organization of an organism (using humans as an example) is shown below.
Understanding all levels of biological organization is required to generate meaningful insight into the processes of life. However, even the cell, the smallest living unit of an organism, is very complex. Each cell contains DNA that holds genetic code. The genes in DNA encode protein molecules that carry out all the functions necessary for life. There are some 42 million protein molecules in a cell. The sheer number of molecules, with their diverse physical structures, chemical features, and interactions, make biology complex. These intricacies of life are the reason centuries of advancements in biology have failed to clearly answer questions such as why some people suffer from depression, autism, or Alzheimer's disease, while others do not.
Computational biology aims to help biologists deal with this complexity by utilizing mathematical, statistical, and computational methods. For example, scientists are interested in understanding which genetic mutations make healthy cells cancerous. One approach is to examine mutations in healthy and cancerous cells of a large sample of people, using computational methods to detect patterns. This can lead to new treatments or even ways to prevent the disease. Below are some additional examples of how computational biology is helping biology researchers, doctors, pharmaceutical companies, and public health officials.

Impact
-
![rftasdfasdfasdf]()
"Omics" Research
Simplify the analysis of large-scale biological data sets, which is generated by the growing interest in “omics” (genomics, transcriptomics, proteomics, metabolomics, etc.)
-
![]()
Systems biology
Simulate the interactions between different components, such as genes, proteins, and metabolic pathways, and help integrate data from various sources to build comprehensive models. These models help in understanding how biological systems function as a whole, which in turn will help discovery of therapeutic interventions
-
![]()
Structural biology
Simulate physical movements of atoms and molecules over time, providing insights into the dynamics of biological processes and interactions, and how molecules such as protein function by predicting their three-dimensional structure from amino acid sequence. These insights aid in structure-based drug design.
-
![]()
Pharmacogenomics
Provide insights into how certain genetic variants impact an individual’s response to certain medications to help develop personalized treatment options.
-
![]()
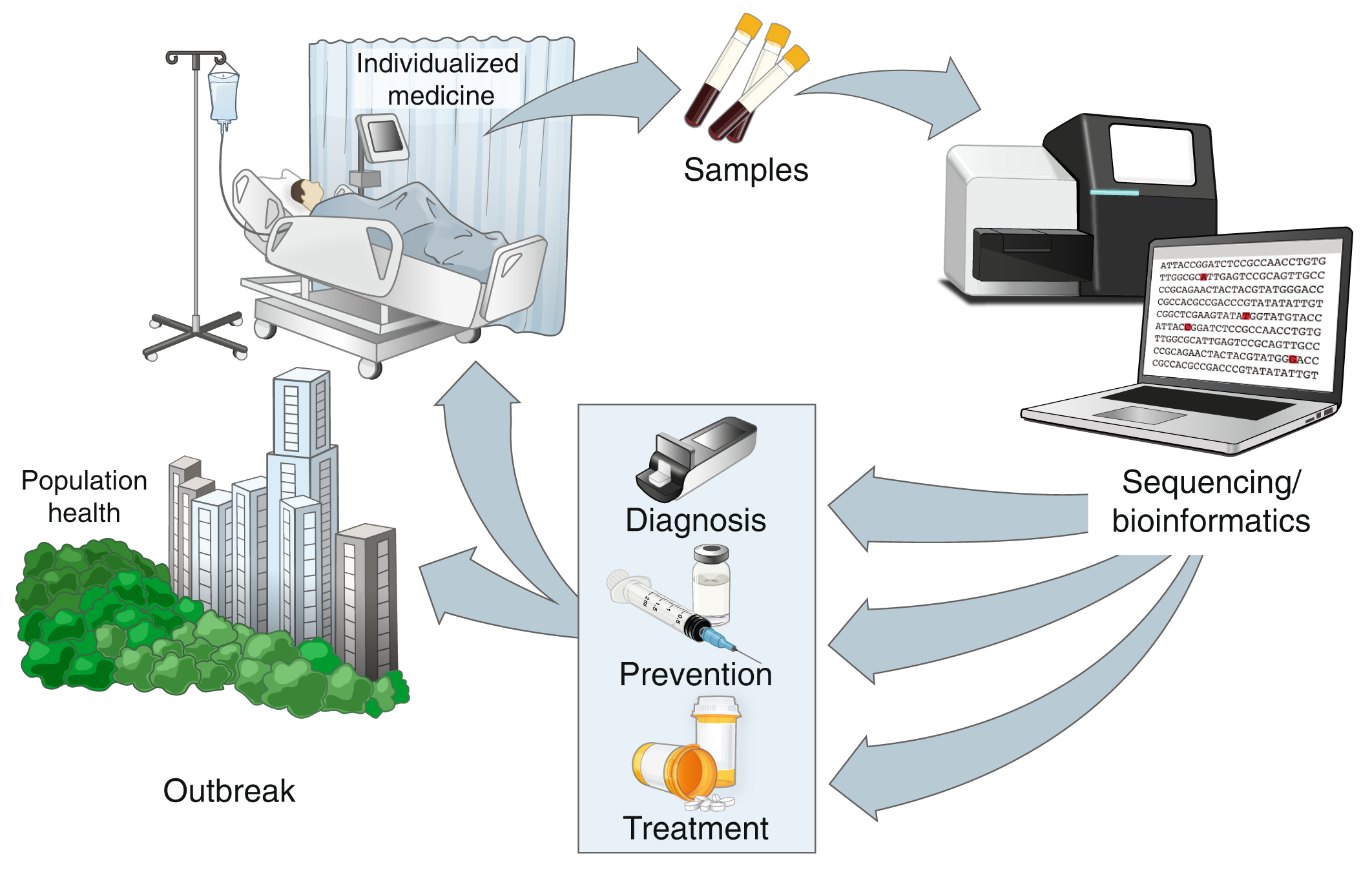
Disease diagnosis and prognosis
Determine quickly if a patient has certain genetic mutation, for instance based on their blood smear images, to help doctors personalize care.
-
![]()
Healthcare based on wireless health data
Transform continuous streams of large quantities of data received from health monitoring devices into information to aid in data-driven medical care.
-
![]()
Public Health
Track viral evolution during infectious disease spread by analyzing samples of sequenced pathogens of infected patients and identifying viral variants to enable public health officials determine the most effective course of action.
-
![]()
Drug discovery
Aid in characterization of drug-binding molecular mechanisms, and identification of a biological target such as a molecular protein that is predicted to bind well with the drug, thus reducing the time and cost associated with finding drug candidates.
-
![]()
Neuroscience
Aid in modeling neural processes, simulating brain activity, and analyzing neuroimaging data to help neuroscientists understand the function of the nervous system.
-
![]()
Bioengineering
Help design the DNA fragments that when inserted into living cells will result in re-engineered biological systems (e.g. genetic engineering of bacteria to produce chemicals and pharmaceuticals, changing genetic materials in plants to improve crop yields or design drought-resistant plants).





Tools and Techniques in Computational Biology
Sequence Alignment
Sequence alignment involves arranging sequences of DNA, RNA, or proteins to identify regions of similarity that may indicate functional, structural, or evolutionary relationships. Techniques include:
Pairwise Alignment: Aligning two sequences to identify regions of similarity. Tools include BLAST (Basic Local Alignment Search Tool) and FASTA.
Multiple Sequence Alignment: Aligning three or more sequences to find conserved regions and infer evolutionary relationships. Tools include Clustal Omega and MUSCLE.

Phylogenetic tree for all of life. Source: Madeleine Price Ball

Data normalization and standardization. Source: Someka
Phylogenetic Trees
Phylogenetic trees represent the evolutionary relationships among various biological species based on their genetic information. Computational methods used in constructing phylogenetic trees include:
Distance-Based Methods: Such as Neighbor-Joining, which constructs trees based on pairwise distance measurements between sequences.
Character-Based Methods: Such as Maximum Parsimony and Maximum Likelihood, which use models of sequence evolution to find the tree that best explains the observed data.
Molecular Dynamics Simulations
Molecular dynamics simulations model the behavior of biological molecules over time by solving Newton's equations of motion for atoms in a molecular system. These simulations provide detailed information about molecular conformations, interactions, and dynamics. Key applications include studying protein-ligand interactions and conformational changes in biomolecules.

Data visualization for omics research. Source: Elia Brodsky

A computer application provides a view of molecular and protein dynamics. Source: Cresset
Data Management
As with any computational approach, the success of computational biology depends on data management, which involves:
Data Normalization: Correcting biases in data collected on a given biological phenomena by different instruments, procedures, or researchers to improve the comparability of the data. An example of a data normalization tool is an open-source R package called Normalyer.
Data Mediation: Creating a common model for data, communicating with database wrappers, and presenting the data to the user application. Kleisli system, and K2 are examples of data mediation (middleware) tools.
Data Ontology: Linking varying formats of data pertinent to one or more biological phenomena to address integration challenges posed by semantic differences inherent in biological research data. Examples include Biological and Environmental Research Ontology, Cell Line Ontology, Gene Ontology.
Data Annotation: Creating and maintaining machine readable “data about data” to improve the utility of data (e.g. information that identifies whether a gene sequence is transcription or translation for a database that contains raw DNA sequences, information about who created the database, when it was created and modified). NIH’s Database for Annotation, Visualization and Integrated Discovery (DAVID) is an example.
Data Visualization: Creating heatmaps, bar charts, scatter plots, and interactive visualizations to allow researchers to effectively communicate and interpret complex biological data such as DNA sequence features, gene expression patterns, protein-protein interactions etc.
Machine Learning
Machine learning algorithms are increasingly used in computational biology to analyze large and complex data sets. Unlike classical statistics, they do not rely on strict assumptions and get better iteratively as more data is passed through the algorithm. Applications include:
Predictive Modeling: Predicting biological outcomes based on input data, such as predicting disease risk from genetic profiles.
Pattern Recognition: Identifying patterns and clusters in high-dimensional data, such as detecting cancer subtypes from gene expression data.
Image Analysis: Analyzing biomedical images, such as identifying and quantifying cells in microscopy images.
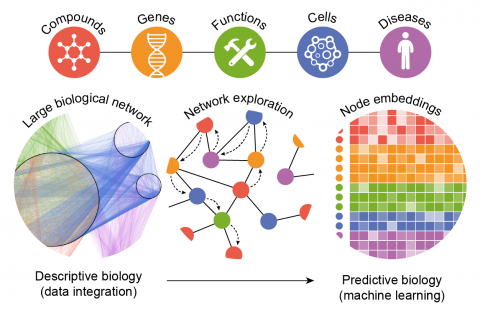
Recent Advances and Applications
CRISPR and Genome Editing
CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) technology has revolutionized genome editing. Computational biology has been essential in designing CRISPR guides, predicting off-target effects, and optimizing editing efficiency. This technology holds promise for treating genetic disorders, improving crop traits, and advancing synthetic biology.
Personalized Medicine
Personalized medicine aims to tailor medical treatments to individual patients based on their genetic, environmental, and lifestyle factors. Computational biology enables the integration of diverse data types (genomic, proteomic, clinical) to develop personalized therapeutic strategies, predict treatment responses, and identify potential side effects.
COVID-19 Research
During the COVID-19 pandemic, computational biology played a crucial role in understanding the virus's genome, tracking its mutations, and developing vaccines. Computational models predicted the spread of the virus, identified potential drug targets, and facilitated the rapid development of mRNA vaccines.



Future Directions
Continuous advancements in computational methods and technology, and ever-reducing costs of computing and data storage will pave the way for several more exciting applications of computational biology, thus helping answer several current unanswered biological questions. Some key future directions include:
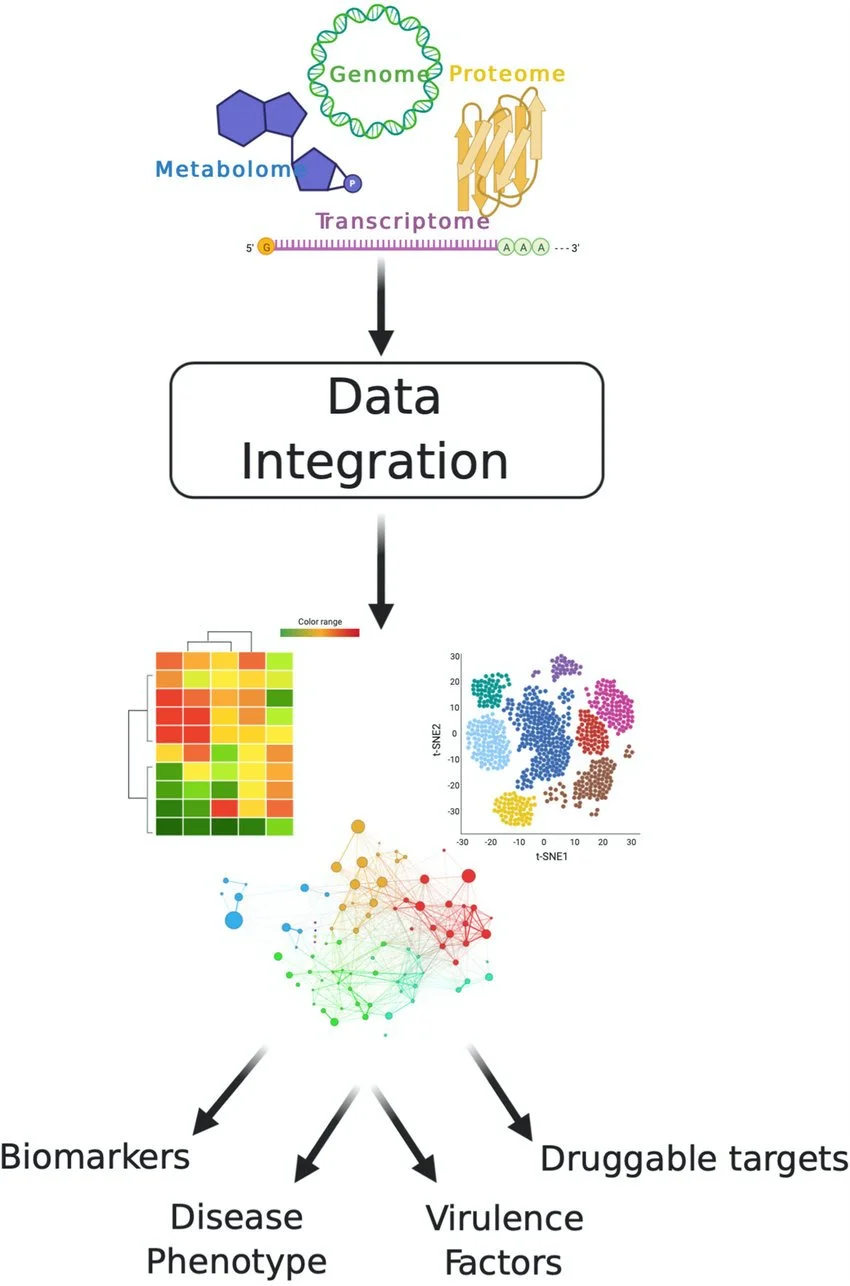
Integration of Multi-Omics Data
Combining data from genomics, proteomics, transcriptomics, and other omics fields to gain a comprehensive understanding of biological systems.
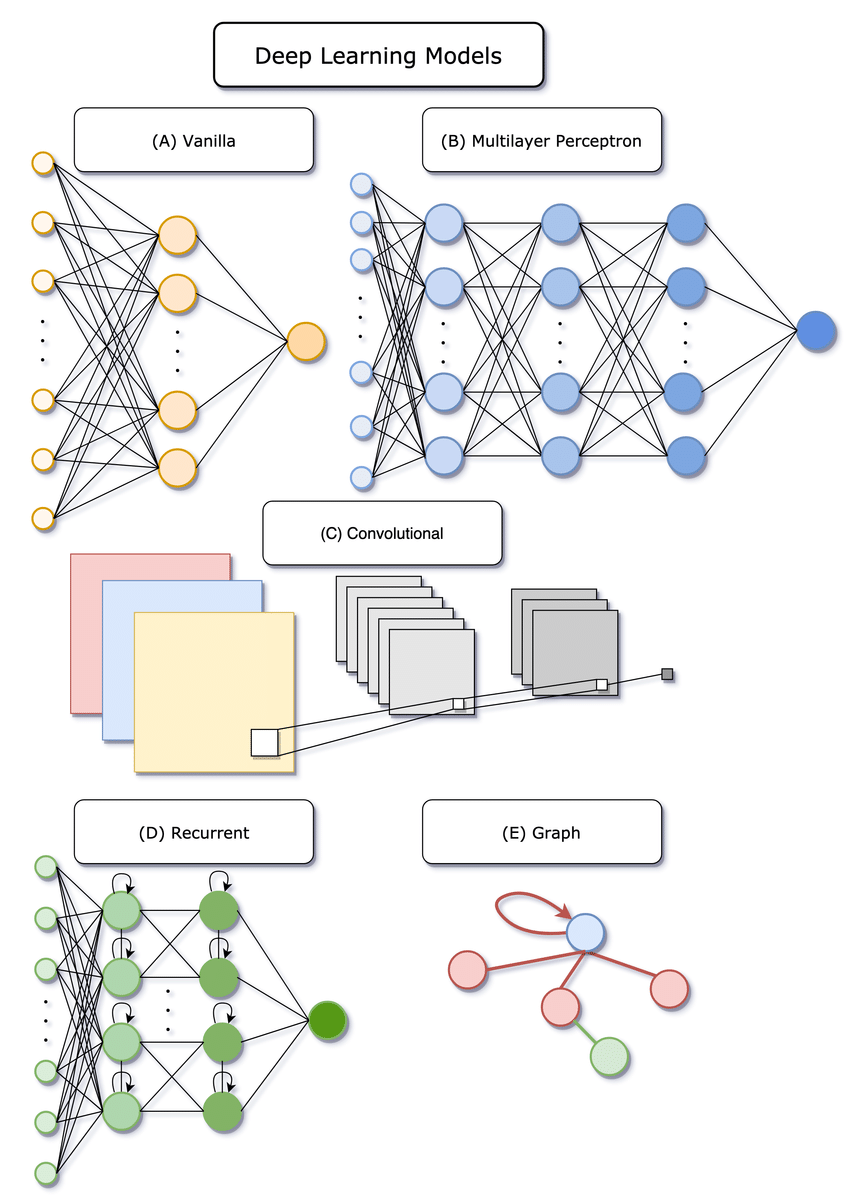
Deep Learning
Leveraging AI and deep learning to uncover complex patterns in biological data, improve predictive models, and accelerate drug discovery.
Quantum Computing
Exploring the potential of quantum computing to solve computationally intensive problems in biology, such as protein folding and molecular simulations.
